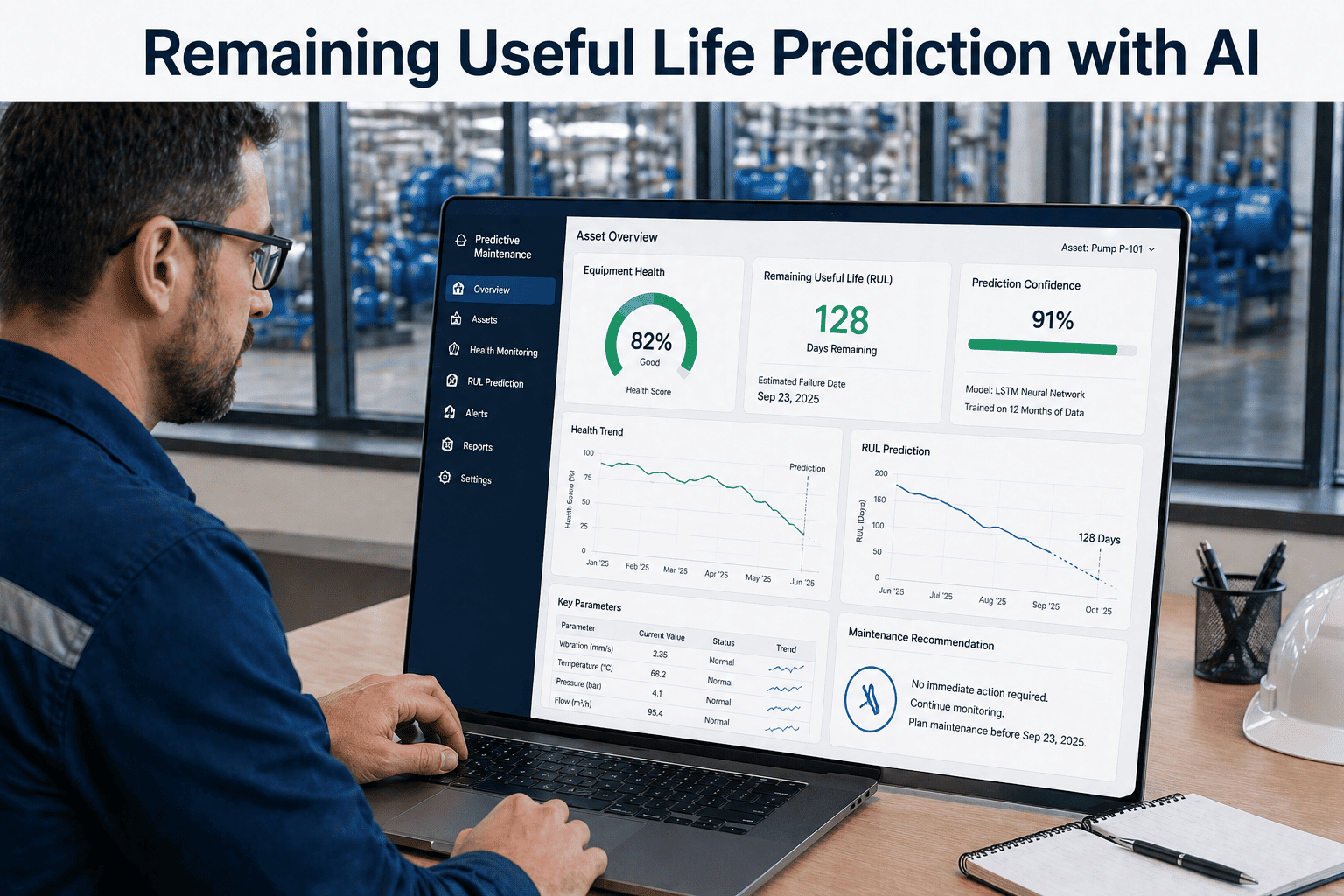
At 03:47 on a Tuesday, a 12,000-rpm centrifugal compressor at a chemical plant in Houston started vibrating 0.3 mm/s above its baseline. No alarm tripped. No technician noticed. The PLC kept running. Eleven days later, the bearing seized — taking the line down for 94 hours and costing $2.1M in lost output and emergency repair. A machine learning model running on the same vibration data flagged the anomaly at 03:51 — four minutes after the drift started — with 91% confidence of bearing degradation within 14 days. That is the gap between data and intelligence. Machine learning anomaly detection closes it. If you want to see the same model running on your assets, you can start a free trial in under three minutes.
AI in MaintenancePredictive AnalyticsAnomaly Detection
Machine Learning Anomaly Detection for Equipment: The Complete 2026 Guide
How unsupervised learning models, sensor fusion, and CMMS automation are catching equipment failures 8–14 days before they happen — and turning maintenance teams from firefighters into forecasters.
94%Detection accuracy with deep learning anomaly models on vibration data
8–14 daysAverage early-warning window before catastrophic equipment failure
67%Reduction in false positives versus rule-based threshold alarms
$98BPredictive maintenance market size projected by 2033
Stop reacting to failures. Start predicting them.OxMaint plugs ML anomaly detection into your existing sensor stack — no data scientist required, live in 5 days.
What Is Machine Learning Anomaly Detection for Equipment?
Machine learning anomaly detection is the use of statistical and deep-learning models to identify equipment behavior that deviates from a learned baseline of normal operation — without anyone manually setting a threshold. Instead of saying "alert me when temperature exceeds 90°C," the model learns what your specific compressor, bearing, or motor looks like when healthy, then flags every meaningful deviation. This is the difference between a smoke alarm and a smoke alarm that knows the difference between toast and fire. For maintenance teams running 500 to 50,000 assets, manual thresholds simply do not scale — and the cost of every false alarm is technician time you do not have. Teams that want to skip the theory can book a demo and see the model running on real industrial data.
01
Supervised Models
Trained on labeled failure data. Highly accurate when you have failure history — limited when failure modes are rare or new. Best for repeatable equipment with rich failure logs.
02
Unsupervised Models
Learn the shape of "normal" without labels — autoencoders, isolation forests, one-class SVMs. The workhorse for industrial assets where 99% of operating data is healthy.
03
Time-Series Models
LSTMs and Transformers trained on sequential sensor streams. Catch slow drift patterns invisible to single-point thresholds — bearing wear, fouling, calibration shift.
04
Hybrid Frameworks
Combine domain rules with deep learning. Reduce false positives by 60–70% versus pure ML, while keeping the ability to detect previously unseen failure modes.
The Stack
The 6-Layer Anomaly Detection Architecture
An ML anomaly detection system is not one model — it is six layers stacked, each doing one job well. Skip a layer and you either drown in false alarms or miss the failures that matter. Here is the architecture that runs at scale.
Sensor Ingestion
Vibration, temperature, pressure, current, acoustic — sampled 1 Hz to 25 kHz. Modern plants generate 1–4 GB/asset/day. Edge agents compress and forward.
Feature Engineering
FFT for frequency-domain features, wavelets for transient events, statistical aggregates per window. Reduces 25,000 raw points to 60 informative features.
Baseline Learning
Autoencoders learn compressed representations of healthy operation. Reconstruction error becomes the anomaly score — typically trained on 30–90 days of data.
Real-Time Scoring
Live sensor readings scored against the model every 1–60 seconds. Edge inference returns anomaly probability in under 200 ms — no cloud round-trip.
Failure Mode Classification
A second model takes the anomaly signature and classifies it: bearing wear, imbalance, misalignment, cavitation, electrical fault. Drives technician dispatch.
CMMS Action Layer
Anomaly + classification + severity converted into a work order with priority, recommended action, parts list, and estimated remaining useful life — all auto-generated.
The Reality
Why Most Plants Cannot Detect the Anomaly Until It Becomes a Failure
Sensor data is everywhere. Intelligence about that data is rare. Here are the six gaps that ML anomaly detection closes — and why traditional CMMS and SCADA cannot close them on their own.
73%
Static Threshold Blindness
73% of industrial alarms are set to fixed values that ignore operating context — speed, load, ambient temperature. Real anomalies live below the threshold; alarms fire on healthy data.
4.8x
Reactive Cost Multiplier
Emergency repairs cost 4.8x more than planned maintenance. Without early-warning ML, every catch becomes a scramble — overtime, expedited parts, lost production.
68%
Alarm Flooding
In flooded environments, 68% of alarms are ignored within the first 90 days. Operators tune out what they cannot triage. ML scoring ranks the 0.4% that actually matter.
42%
Failure-Mode Misdiagnosis
42% of unplanned repairs replace the wrong component first. Without a model that classifies the anomaly signature, technicians rebuild instead of repair.
$260K
Per-Asset Annual Loss
Average cost of one unplanned outage on critical rotating equipment: $260K. Plants running 50+ critical assets see this number compound monthly.
11 weeks
Insight-to-Action Lag
Industry average from "anomaly visible in data" to "work order created" is 11 weeks. ML + CMMS automation collapses it to under 60 seconds.
If any of those numbers describe your plant today, the fix starts with sensor data you already have. Start a free trial and connect your first asset in 10 minutes.
The OxMaint Way
How OxMaint Operationalizes ML Anomaly Detection
OxMaint does not require you to hire data scientists. The ML pipeline ships pre-trained on 40+ million asset-hours of industrial data — your team adds context, reviews flagged anomalies, and OxMaint handles the rest.
Step 1
Connect Your Sensor Stack
Native integrations with 80+ IoT platforms — vibration, thermal, pressure, current, ultrasonic. SCADA, OPC-UA, MQTT supported. Live data flowing in under 24 hours.
Step 2
Auto-Baseline Per Asset
OxMaint trains a per-asset autoencoder on 30 days of healthy operating data. No labels required. Each asset gets its own model — not a one-size-fits-all threshold.
Step 3
Real-Time Anomaly Scoring
Every reading scored against the asset's baseline. Anomaly probability, failure mode prediction, and remaining useful life update on a 60-second cycle.
Step 4
Auto Work-Order Generation
Anomalies above the action threshold create work orders with severity, recommended task, technician skill match, and required spare parts — pre-staged from inventory.
Step 5
Closed-Loop Feedback
When a technician closes the work order, the actual root cause feeds back into the model. Each completed repair makes every future prediction more accurate.
Step 6
Portfolio-Level Visibility
Single dashboard across every site, every asset class. CapEx forecasts updated weekly using model-driven RUL estimates — investor-grade reporting out of the box.
Every step here is live in OxMaint today — not on a roadmap. Book a demo to see it on your asset categories.
Side By Side
Threshold Alarms vs ML Anomaly Detection
Capability
Threshold Alarms
ML Anomaly Detection
Setup time per asset
2–6 hours of expert tuning
30 days of auto-baselining, zero manual config
False positive rate
40–60% in dynamic operations
3–8% with autoencoder + classifier stack
Detection lead time
Hours to none — fires at failure
8–14 days median early warning
Adapts to changing conditions
No — manual re-tuning required
Yes — incremental learning continuously
Detects unknown failure modes
No — only what was pre-defined
Yes — flags any deviation from learned normal
Failure-mode classification
Manual investigation required
Auto-classified across 12+ fault types
Cost per asset per year
High labor cost in tuning + investigation
Sub-$50/asset with shared infrastructure
Closed-loop CMMS integration
Email alert at best
Auto work order with parts, skills, priority
Measured Outcomes
What Plants Get After 12 Months on ML Anomaly Detection
73%
Reduction in unplanned downtime — failures caught 8–14 days early move from emergency to planned
42%
Lower total maintenance spend — overtime, expedites, and rebuild costs collapse
3.2x
Increase in MTBF on critical rotating equipment in the first year
94%
Anomaly detection accuracy on validated industrial datasets — published research benchmark
11 mo
Average payback period including software, sensors, and training
67%
Fewer false positives versus existing threshold-based alarm systems
$2.1M
Median annual saving on a 200-asset rotating equipment portfolio
21%
CAGR of the global predictive maintenance market through 2033
FAQs
Frequently Asked Questions
How much sensor data do we need before ML anomaly detection actually works?
Most production-grade autoencoder models reach stable performance after 30 days of healthy operating data per asset. For slow-cycle assets like batch reactors or seasonal equipment, OxMaint's transfer-learning starter models cut this to 7–10 days by leveraging patterns from comparable assets. You do not need to wait 12 months to see value.
Will the model produce false positives that overwhelm our team?
Modern hybrid frameworks bring false-positive rates to 3–8%, compared to 40–60% for threshold systems. OxMaint adds a confidence threshold and severity classification, so only anomalies above your action level create work orders. Your team sees the 0.4% that matter — not the noise.
Do we need a data scientist on staff to run this?
No. OxMaint ships pre-trained models for 200+ asset categories and handles per-asset baselining automatically. Maintenance managers tune severity thresholds and review flagged anomalies — that is the entire workflow. Plants live in 5 days, no ML expertise required.
How does ML anomaly detection coexist with our existing CMMS?
It does not coexist — it replaces the trigger logic. OxMaint is itself the CMMS, with ML running natively. Anomaly scoring, failure-mode classification, and work-order generation happen in one system. No duct tape between three vendors. Book a demo to see the unified workflow.
Trusted by Maintenance Teams Across 40+ Countries
Catch the Failure Before It Catches You
OxMaint connects to your sensors, learns your assets, and flags anomalies 8–14 days before failure — with auto-generated work orders, parts, and technician dispatch. Live in 5 days. No data scientist required.